この記事でわかること
今回のテーマは、世界的に人気の高いサーチエンジンElasticsearchを含むパッケージ「Elastic Stack」です。※
Elastic Stackは応用次第でいろいろな用途に使えますが、ここでは初めて扱うエンジニアの方向けに、その概要と使い方のサンプルをご紹介し、導入イメージを掴んでいただきたいと思います。
※DB-Engines Ranking of Search Engines | solid IT
https://db-engines.com/en/ranking/search+engine
目次
- Elastic Stackとは?何ができる?
- 利用方法、料金は?
- Windows上でTwitter可視化環境を作ってみる
1. Elastic Stackとは?何ができる?
Elastic StackはサーチエンジンElasticsearchと、データ取り込みツール、可視化アプリがパッケージとなったプラットフォームです。
公式サイトがログ解析・可視化のデモサイトを公開しているので、おおよそイメージがつかめるのではないでしょうか。
https://demo.elastic.co/app/kibana#/dashboard/
Apacheのアクセスログを見てみると、↓のようなイメージです。
メジャーなミドルウェアについては、データ取り込みモジュールと可視化設定があらかじめ用意されています。
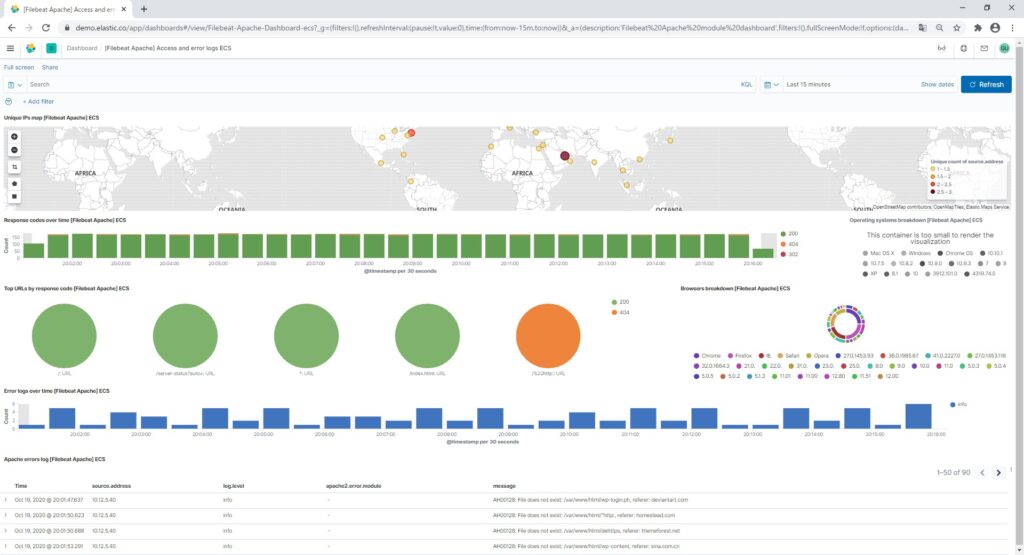
今回試してみたTwitter解析についてもプラグインが用意されているので、ノンプログラミングで完成します。
また、サーチエンジンですので、検索ワードの文節を解析して近いワードも拾ってくれ、関連度が高い順にソートしてくれたりします。
※デフォルトでは日本語の解析に対応していませんが、プラグインで追加可能です。
以下がElastic Stackの基本構成になります。
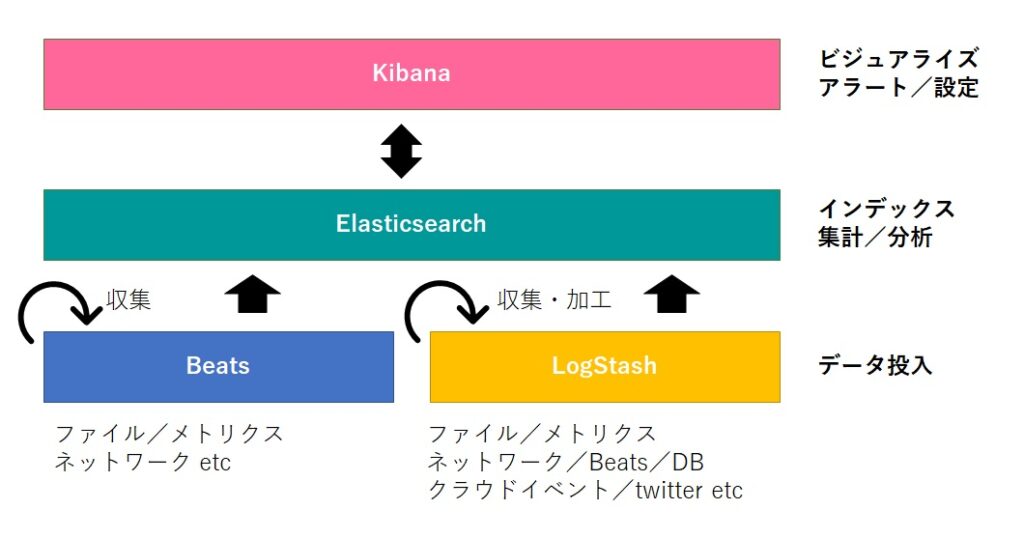
Elasticseachへデータを投入する方法は大きく分けて2つあり、ひとつめがBeatsやLogstashなどのデータ収集エージェントを利用するノンプログラミングな方法、ふたつめがbulk APIを使用する方法です。Elasticsearchはデータが投入されるとインデックスし、Kibanaから登録された集計ジョブや、APIで要求されたクエリを実行します。
BeatsとLogstashの役割がかぶっているため補足しますが、BeatsとLogstashには次のような違いがあります。
- Beats
- プリセットされたパイプラインで、すぐにデータの取り込みを始められるモジュールが用意されている
- 軽量
- ユーザー定義によるデータの加工はほぼできない
- Logstash
- 入力、加工、出力プラグインを組み合わせ、自由度高くパイプラインを作成できる
- ユーザー定義によるデータの加工ができる
- Beatsで対応していないデータの取り込みができる
2. 利用方法、料金は?
利用する方法には次の3つがあります。
- AWSなどのパブリッククラウド上でサービスを使用する
- オンプレミスにセルフマネージドクラウドで導入する
- 個別にダウンロード・インストールする
それぞれにサブスクリプションプランが設定されていますが、例えばオンプレミスに個別に入れていくElastic Stackサブスクリプションでは、無料のOSSとベーシック、有料プラン3種から選べます。
サービス内容が改定される可能性がありますので、詳しくは下記を確認してください。
https://www.elastic.co/jp/subscriptions
私は今回OSSで試してみましたが、ベーシックはユーザー登録するだけでElasticsearch単独の機能のほとんどが使えそうです。ベーシックまでで使えない機能のうち、気になるものはこのあたりでしょうか。
- 統合認証系(AD、SSO)
- メールやSlackでのアラート通知(Kibana上でのアラートは可)
- JDBCドライバー、ODBCドライバー、Tableauコネクター
- 機械学習
既存システムと連携するには有料オプションを検討する必要がありそうです。
なお、AWSで試す場合は14日間は無料です。
3. Windows上でTwitter可視化環境を作ってみる
環境はWindows10 Pro、OpenJDK14を使用して進めていきます。
Javaのバージョンについては↓のページからElasticsearchとLogstashのサポートバージョンを確認してください。
https://www.elastic.co/jp/support/matrix#matrix_jvm
3.1 Elasticsearch、Kibanaのインストール
まずはElasticsearchとkibanaのインストールと起動確認です。
基本的にガイドの通りに進めていきます。
https://www.elastic.co/guide/en/elastic-stack-get-started/current/get-started-elastic-stack.html
ガイドではcurlを使用していますが、Windowsには入っていないので、↓のサイトからZIPをダウンロードしてくることにします。
https://www.elastic.co/jp/start
ElasticsearchのZIPファイルをダウンロードして適当なパスに解凍します。解凍先のbin配下にあるbatを実行すればOKです。

ポートはログに出力されている9200になります。起動確認します。
OKです。
次のKibanaに行きましょう。手順はElasticsearchと同様です。
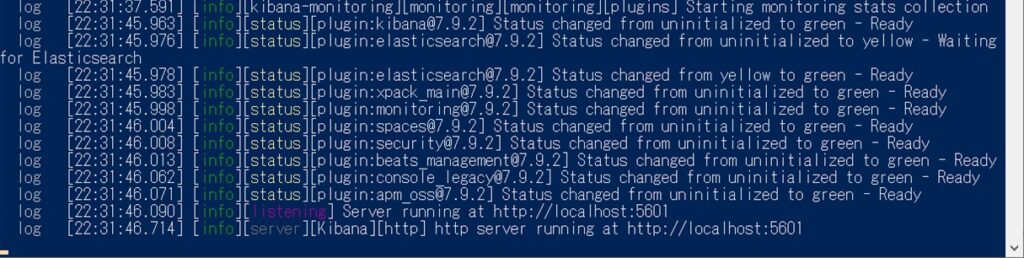
ログに出力されているhttp://localhost:5601へアクセスします。
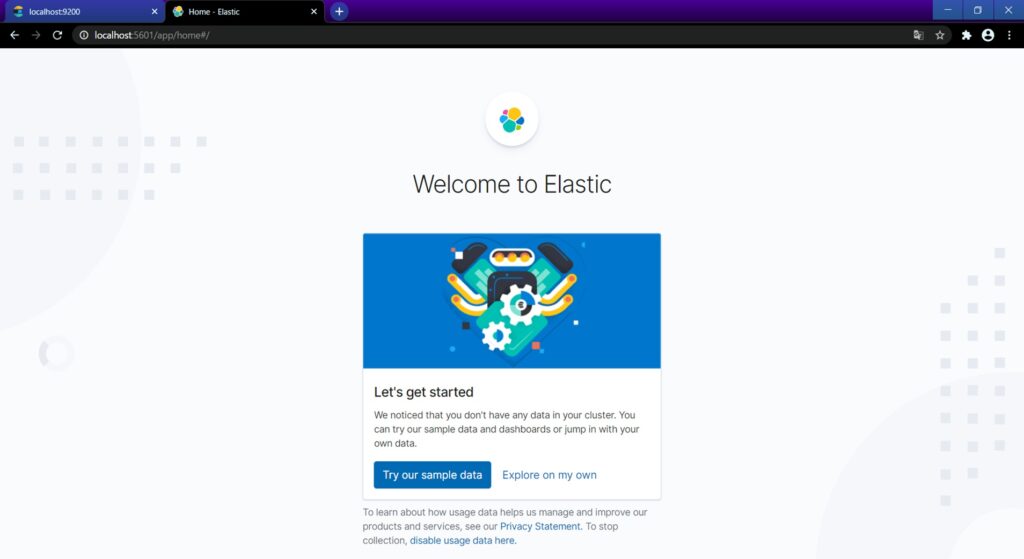
これでElasticsearchとKibanaについては完了です。
3.2 Logstashのインストール
↓のサイトからZIPをダウンロードしてきます。
https://www.elastic.co/jp/downloads/logstash
適当な場所で解凍したら、下記のガイドにあるファーストイベントを試してみます。
https://www.elastic.co/guide/en/logstash/current/first-event.html
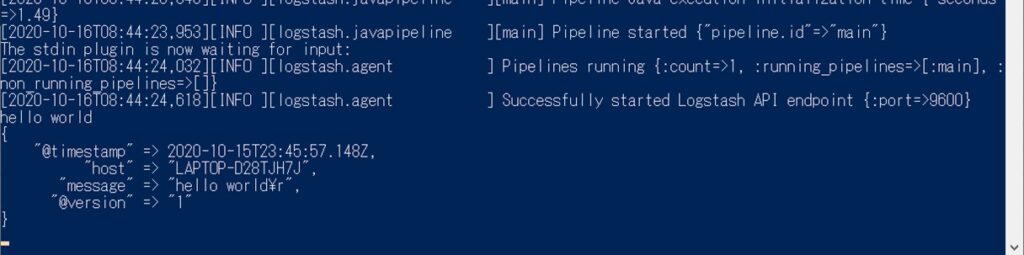
bin配下に移動してガイドのコマンドを実行。
.\logstash -e 'input { stdin { } } output { stdout {} }'

起動ログが確認できたら、同じコンソールで「hello world」と打ち込みます。標準入力stdinにタイムスタンプもろもろが付いて標準出力stdoutに出力されます。
今回filterは使用していませんが、input、filter、outputの3フィールドで、それぞれ入力、加工、出力プラグインを設定することになります。
3.3 Twitter APIの準備
Twitter APIを利用するには、下記URLから利用申請をして承認される必要があります。英文でデータの利用目的などに答えていく必要がありますが、案内通りに進めていけばOKです。
https://developer.twitter.com/en/apps
申請してしばらく待つと、メールで初期設定リンクが送られてきます。
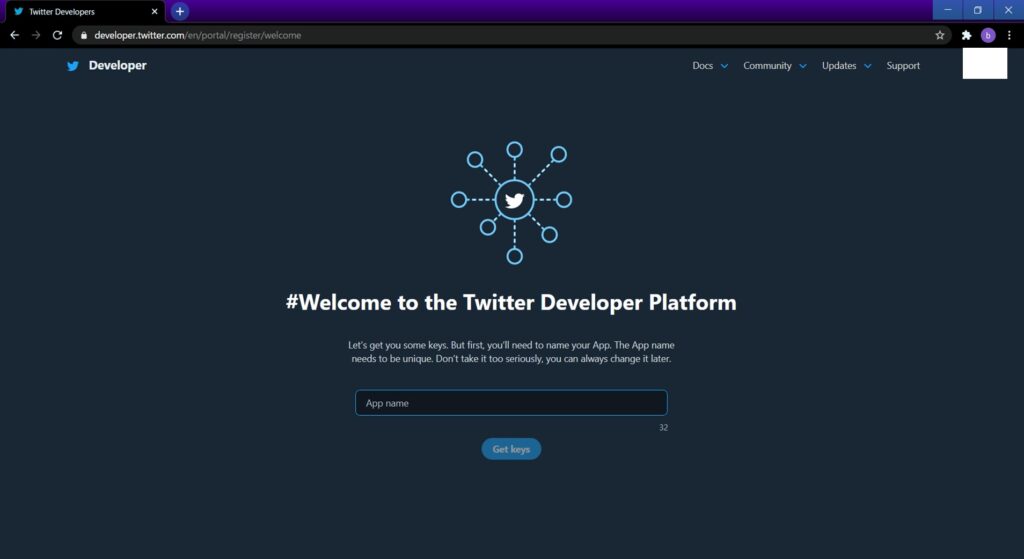
App nameを入れてGet keysで進むと下記が表示されます。
- API key ←後ほど使用
- API secret key ←後ほど使用
- Bearer token
API keyとAPI secret keyは後ほどDeveloper Portalからも確認できますが、ここで控えておきます。
他に必要なキーも集めていきます。
↓にアクセスし、サイドメニューの「Projects & Apps > Overview」を開きます。
https://developer.twitter.com/en/portal/dashboard
先ほどApp nameを入力したエントリーの鍵ボタンを押します。
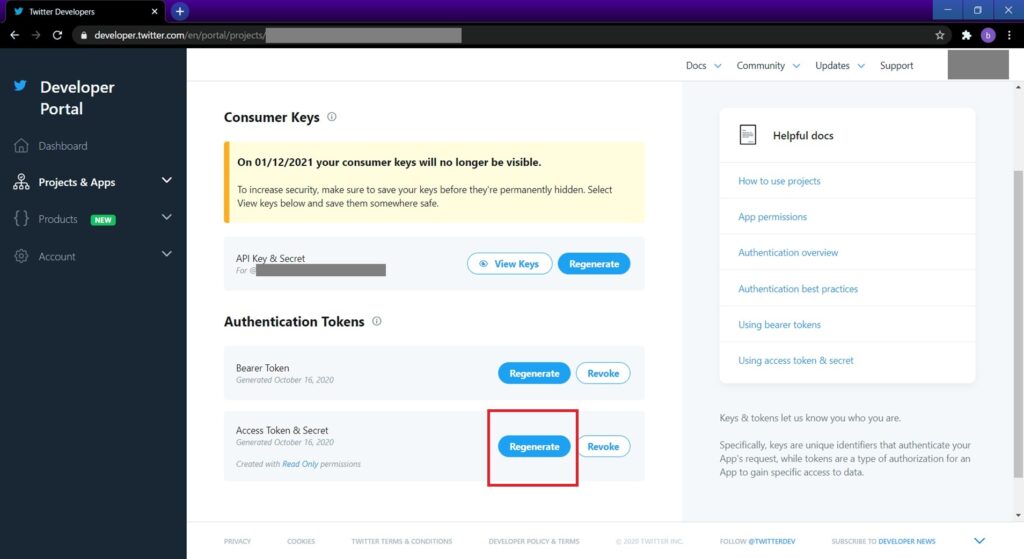
開かれたConsumer Key画面でAccess Token & Secretの赤枠部分のボタンを押すと下記が生成できます。
- Access token ←後ほど使用
- Access secret ←後ほど使用
こちらも控えておいてください。
これでTwitter APIの準備が整いました。
3.4 Elasticsearchへのデータ投入
LogstashからElasticsearchへデータを入れていきます。前述のファーストイベントでは直接コマンドラインに入力していましたが、今回はファイルに設定を定義します。
config配下のlogstash-sample.confをコピーしてlogstash-twitter.confを作成します。
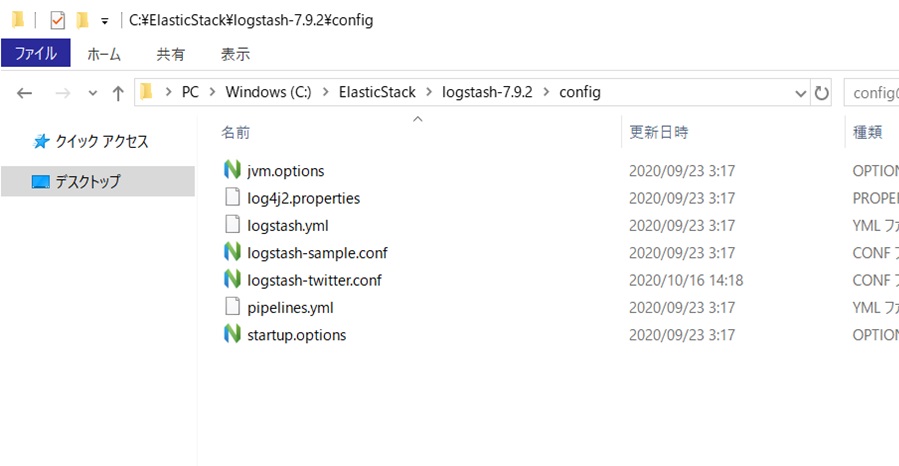
↓を参考に中身を作ります。
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-twitter.html
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
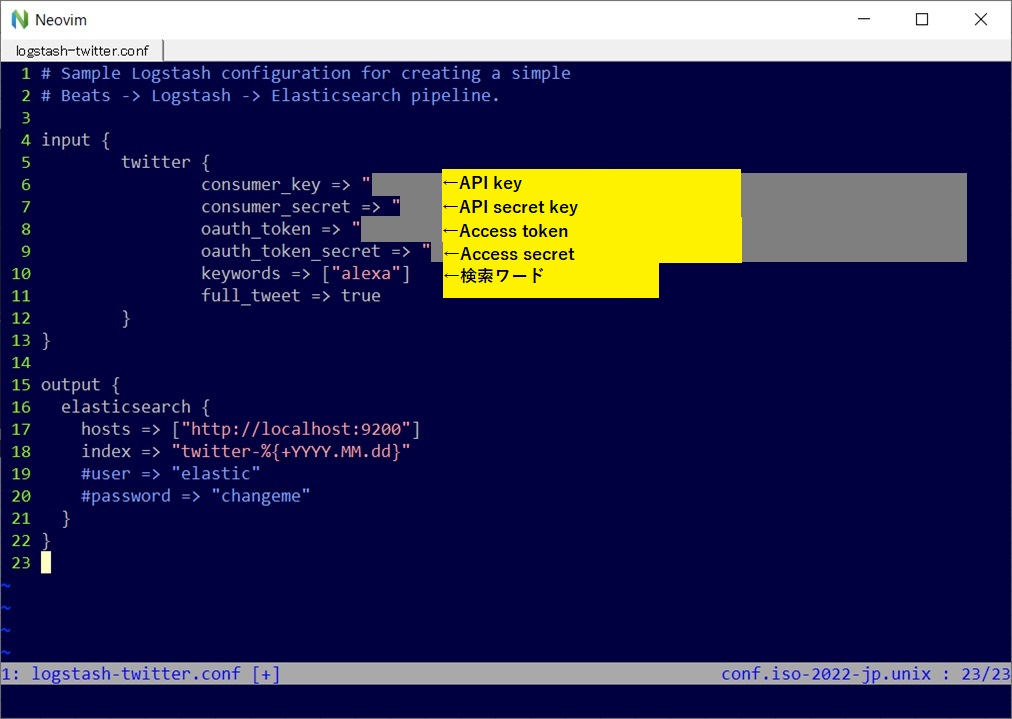
保存して下記コマンドで実行しましょう。
.\bin\logstash -f .\config\logstash-twitter.conf
これでデータの投入が始まりました。
3.5 Kibanaで可視化設定
可視化するためにはデータ取得設定が必要です。ハンバーガーメニューからDiscoverを選択します。
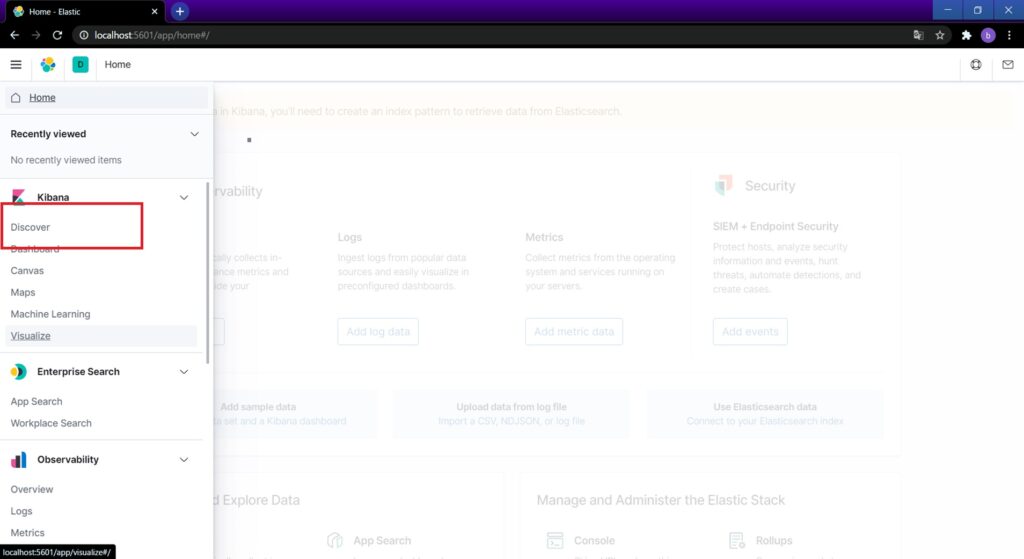
初回であれば、Indexパターンの設定画面が開きます。「twitter」と入れてCreate index patternボタンを押します。
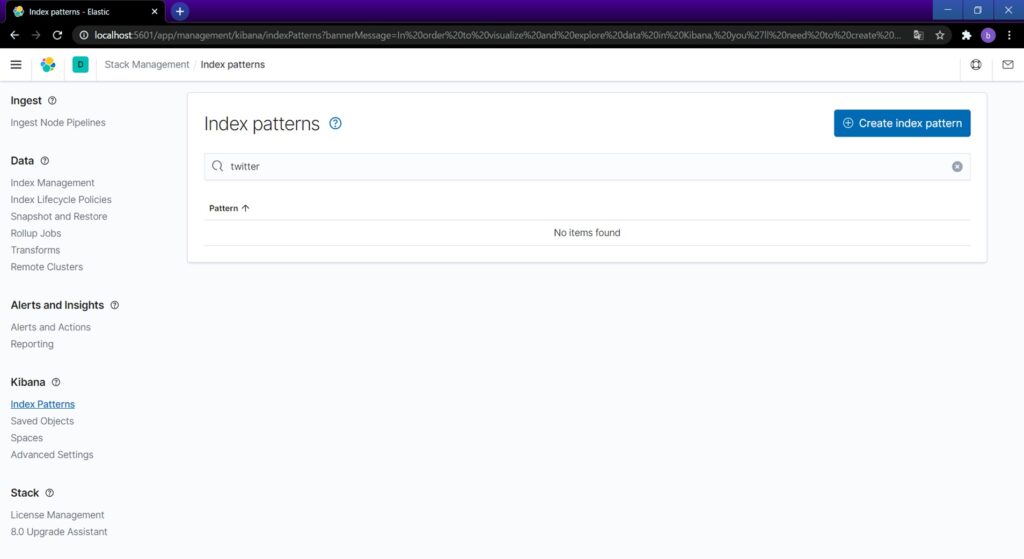
赤枠部分を参照してIndex pattern nameに「twitter-*」を設定し、Next step。
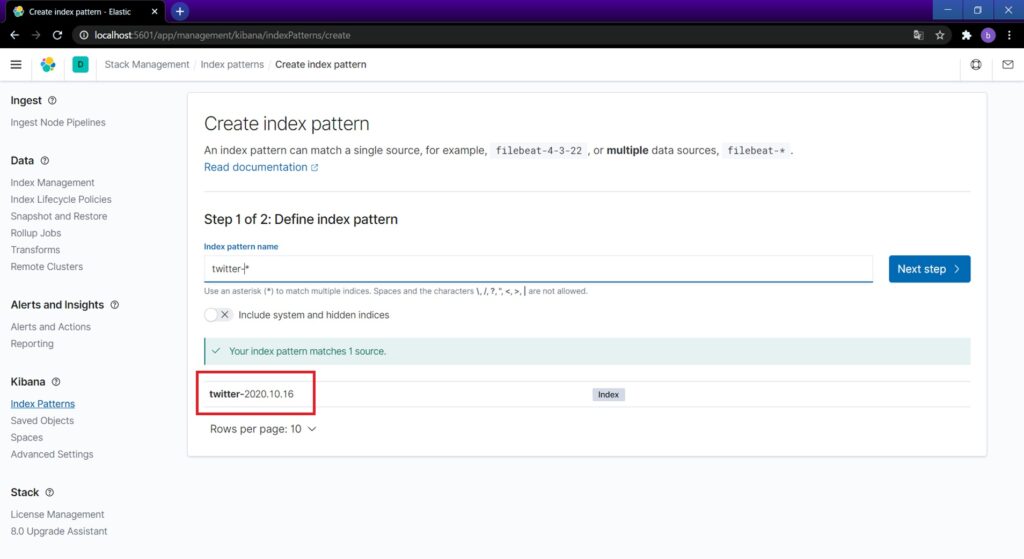
Time fieldに@timestampを指定してCreate index patternを押せば完了です。
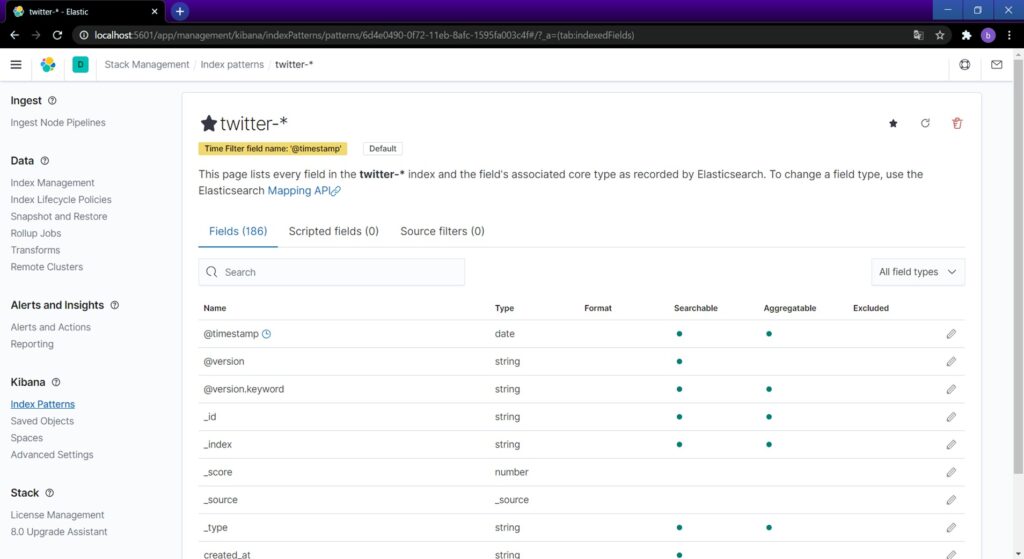
再度Discoverにアクセスすると、↓のようにデータが見られるようになります。
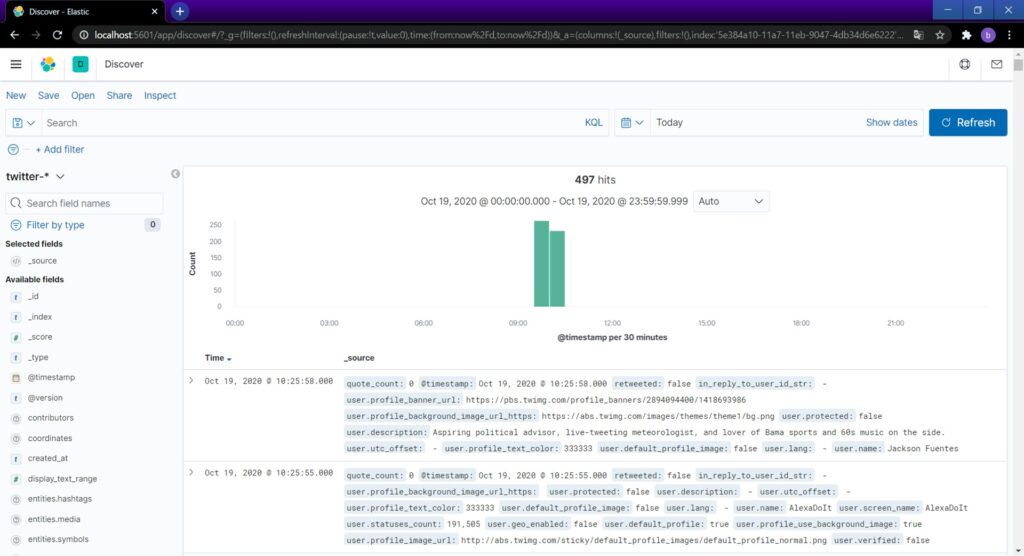
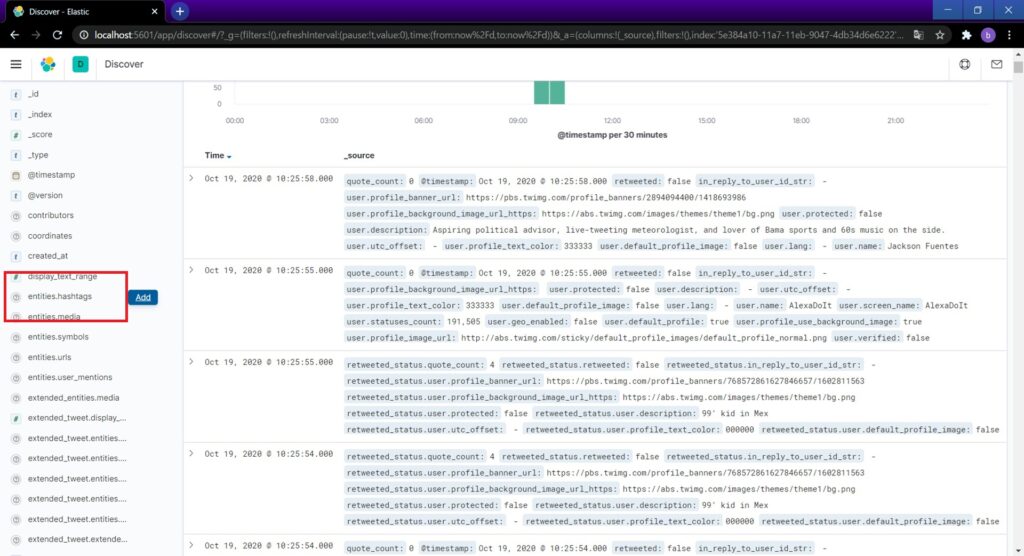
左ペインからデータ取得するフィールドを追加できます。今回はハッシュタグを追加します。
左上のSaveで取得パターンを保存します。
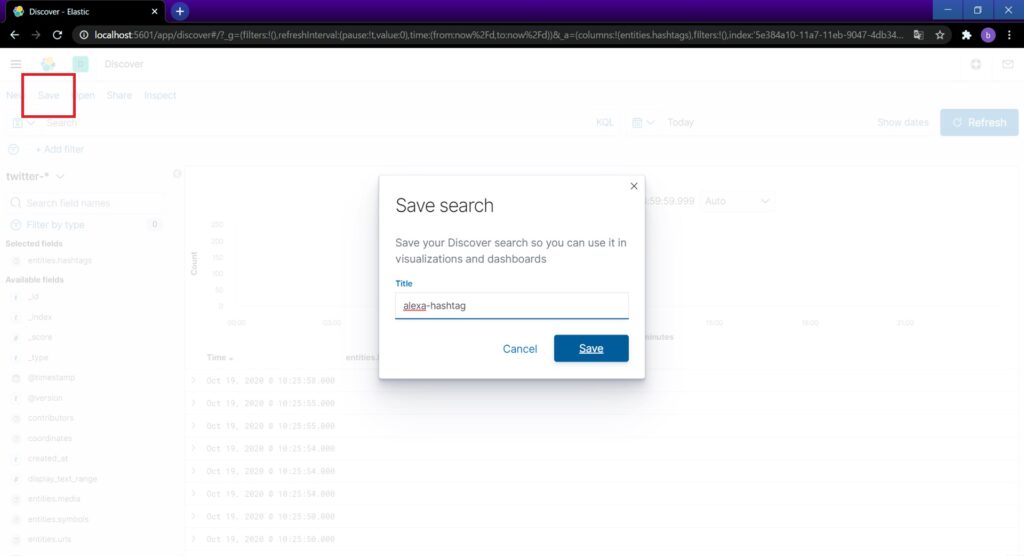
データの取得設定が完了しました。
いよいよ可視化をしていきます。ハンバーガーメニューからVisualizeを選択します。
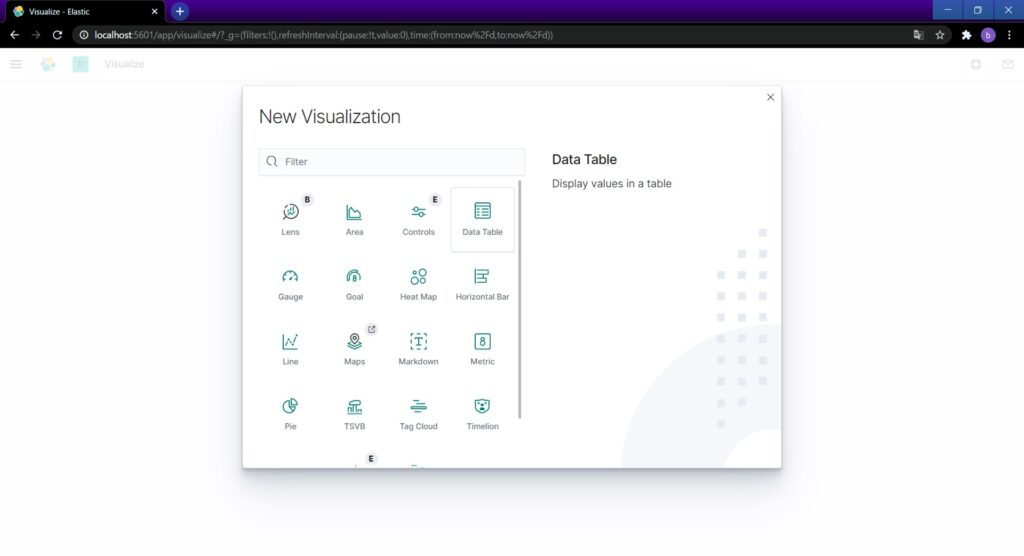
Create new visualizationを押すとグラフの種類が選べます。
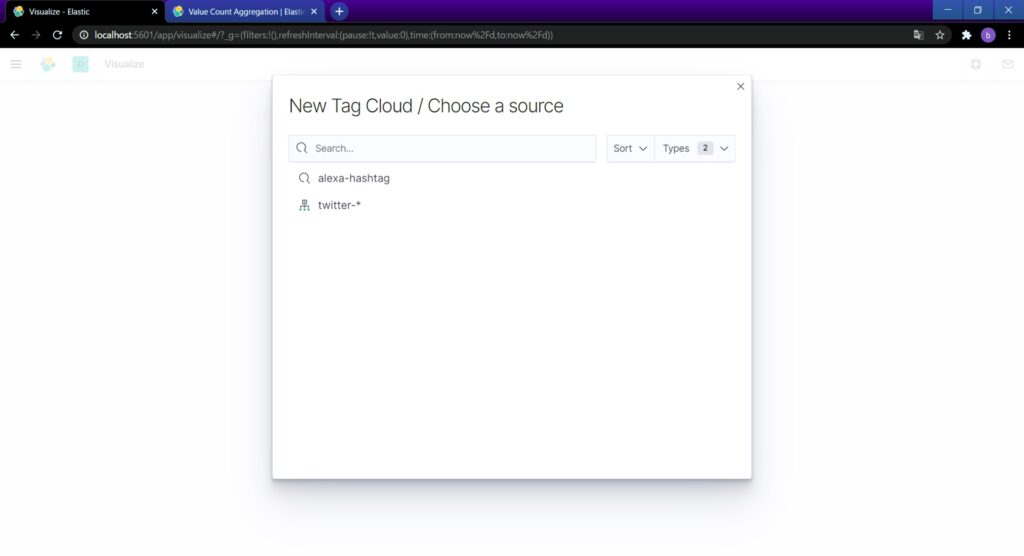
今回はハッシュタグをタグクラウド表示してみます。Tag Cloudを選択。ソースは先ほど作成したalexa-hashtagを使います。
右ペインのBucketsにあるAddを選択し、開いた設定欄に↓のように入力します。
Updateボタンを押すと良い感じに表示されました。
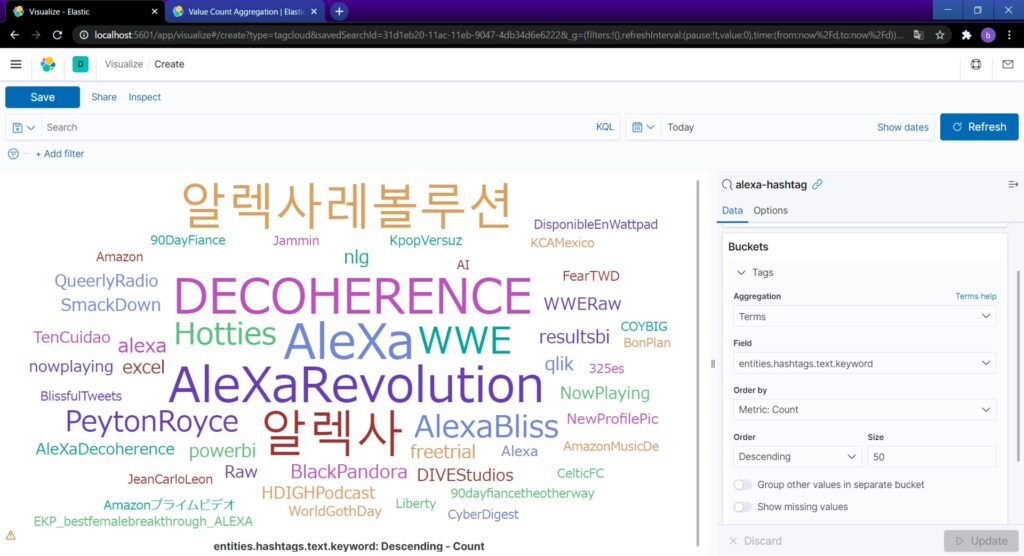
以上です。
Elastic Stackはまさに「使い方次第」といったパッケージですが、活用への入口になればと考え、概要と使い方のサンプルをご紹介してきました。
読者の方に、使い方のアイディア、イメージがわいてくれれば、筆者としては最高の喜びです。